idea开发springboot(多模块)项目,发现使用main方法启动项目jsp页面404。
需要配置Run/Debug configuration。
spring boot–> configuration–>working directory : $MODULE_DIR$
今天最好的表现,是明天最低的要求。
idea开发springboot(多模块)项目,发现使用main方法启动项目jsp页面404。
需要配置Run/Debug configuration。
spring boot–> configuration–>working directory : $MODULE_DIR$
今天最好的表现,是明天最低的要求。
公司内规定的开发模式,所有功能已模块的形式发布,classes目录内没有class文件,每个功能都是一个jar包,放在lib目录内。
有需求需要在原有功能给当地客户定义功能,考虑不侵入原有代码。将新开发的功能单独打一个jar包。
我使用的是 jar cvf test.jar com/xxx/xxx/xxx.class打包,但是发现打的包放到服务器上报的是404说明Spring mvc没有识别到Controller。
使用 jar tf test.jar 可以看到
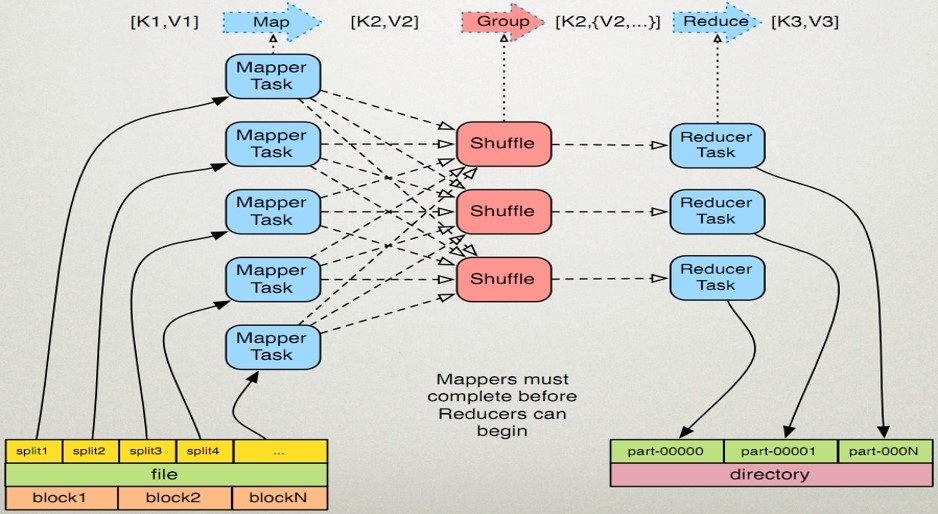
在将map的结果集传递给reduce之前对数据进行了分组(类似于对K2做了group by)
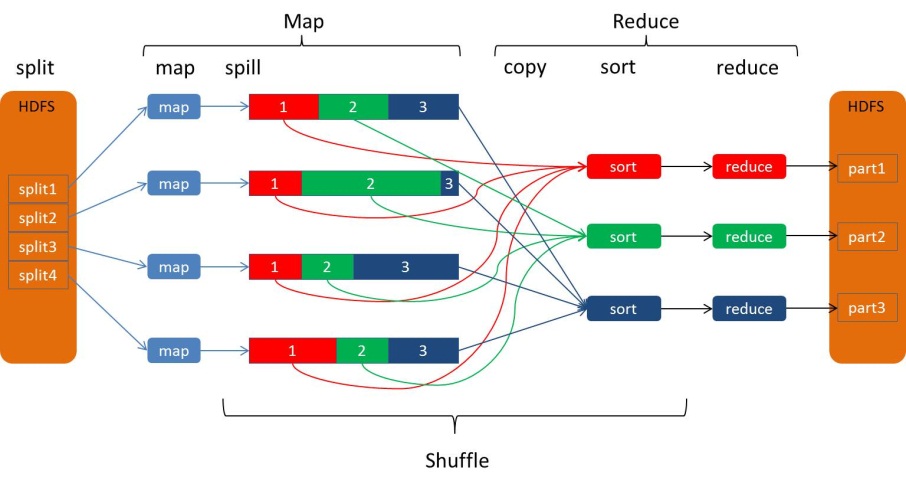
今天最好的表现,是明天最低的要求。
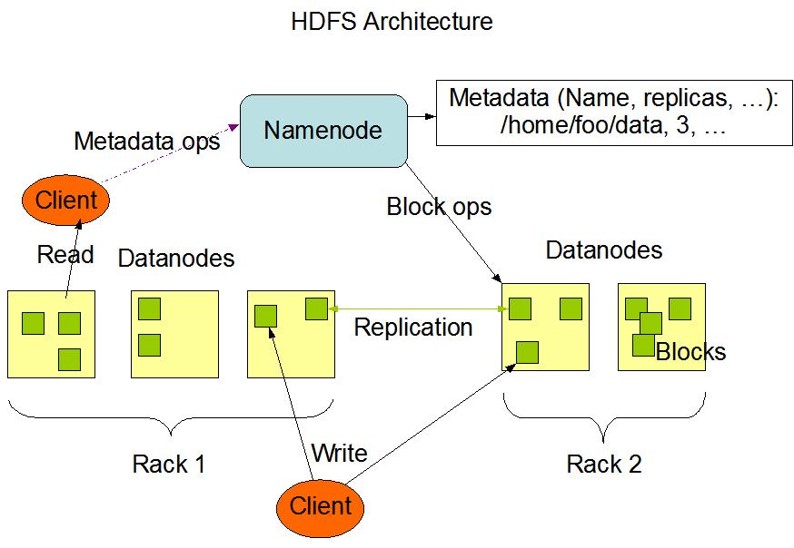
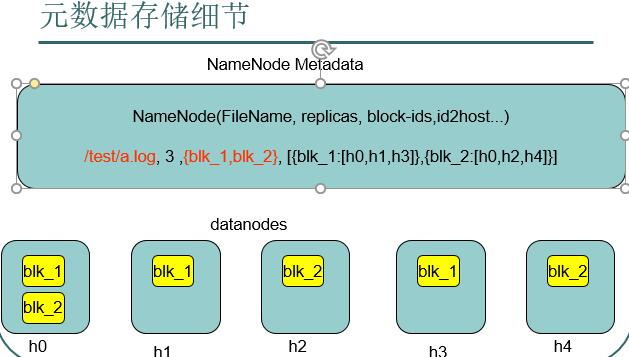
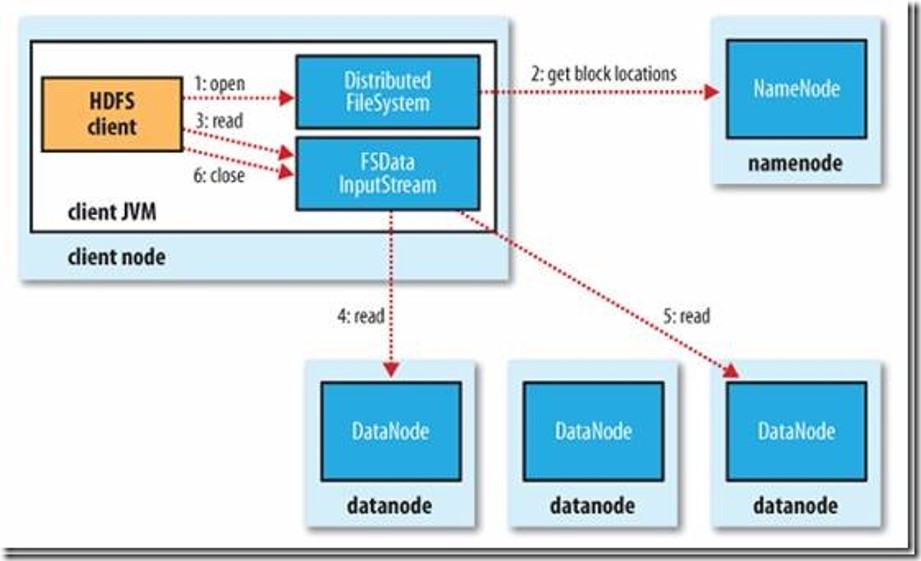
初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件
FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用stream的read()函数开始读取数据。
DFSInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(client)
当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
失败的数据节点将被记录,以后不再连接。
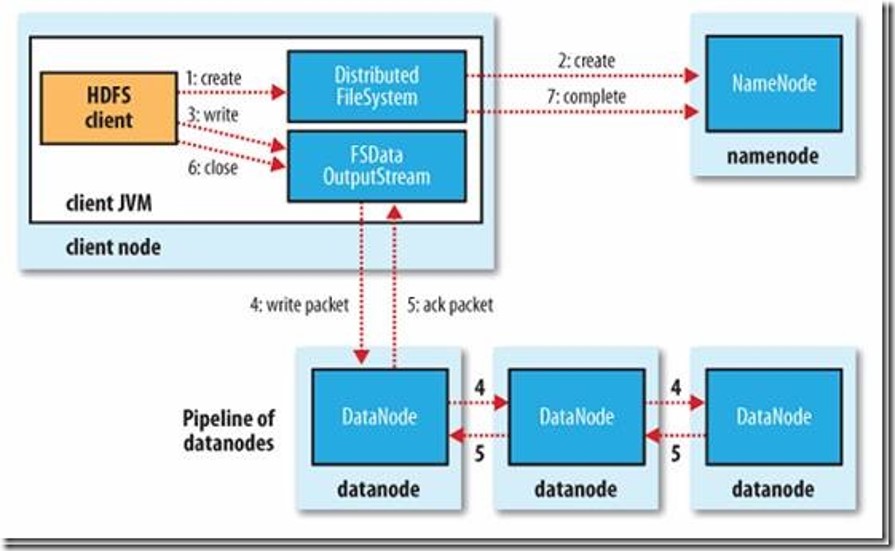
初始化FileSystem,客户端调用create()来创建文件
FileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
FileSystem返回DFSOutputStream,客户端用于写数据,客户端开始写入数据。
DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
如果数据节点在写入的过程中失败,关闭pipeline,将ack queue中的数据块放入data queue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
1 | 1,Hadoop fs –fs [local | <file system URI>]:声明hadoop使用的文件系统,如果不声明的话,使用当前配置文件配置的,按如下顺序查找:hadoop jar里的hadoop-default.xml->$HADOOP_CONF_DIR下的hadoop-default.xml->$HADOOP_CONF_DIR下的hadoop-site.xml。使用local代表将本地文件系统作为hadoop的DFS。如果传递uri做参数,那么就是特定的文件系统作为DFS。 |
今天最好的表现,是明天最低的要求。
1 | public class highlight |