HDFS架构体系
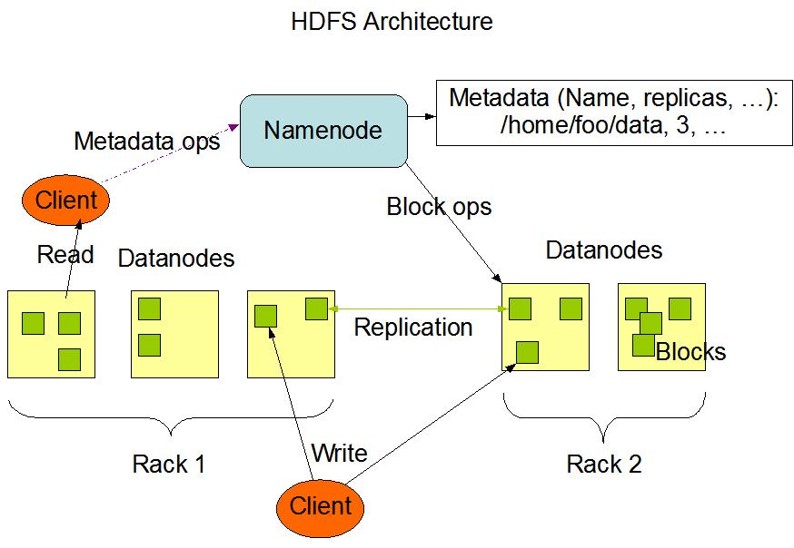
元数据
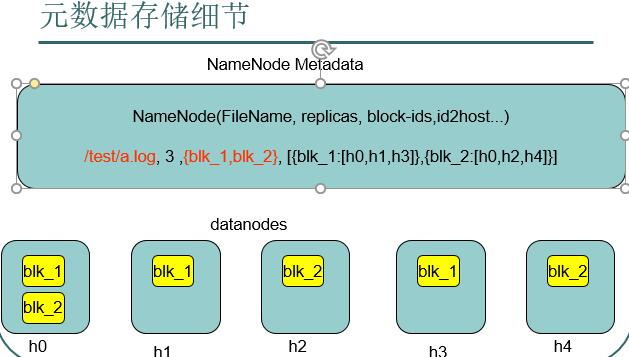
NameNode
- 是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
- 文件包括:
- fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
- edits:操作日志文件。
- fstime:保存最近一次checkpoint的时间
- 以上这些文件是保存在linux的文件系统中。
NameNode工作特点
- Namenode始终在内存中保存metedata,用于处理“读请求”
- 到有“写请求”到来时,namenode会首先写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回
- Hadoop会维护一个fsimage文件,也就是namenode中metedata的镜像,但是fsimage不会随时与namenode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容。Secondary namenode就是用来合并fsimage和edits文件来更新NameNode的metedata的。
SecondaryNameNode
- HA的一个解决方案。但不支持热备。配置即可。
- 执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,替换旧的fsimage.
- 默认在安装在NameNode节点上,但这样…不安全!
secondary namenode的工作流程
- secondary通知namenode切换edits文件
- secondary从namenode获得fsimage和edits(通过http)
- secondary将fsimage载入内存,然后开始合并edits
- secondary将新的fsimage发回给namenode
- namenode用新的fsimage替换旧的fsimage
DataNode
- 提供真实文件数据的存储服务。
- 文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.
不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间 - Replication。多复本。默认是三个。 hdfs-site.xml的dfs.replication属性
HDFS
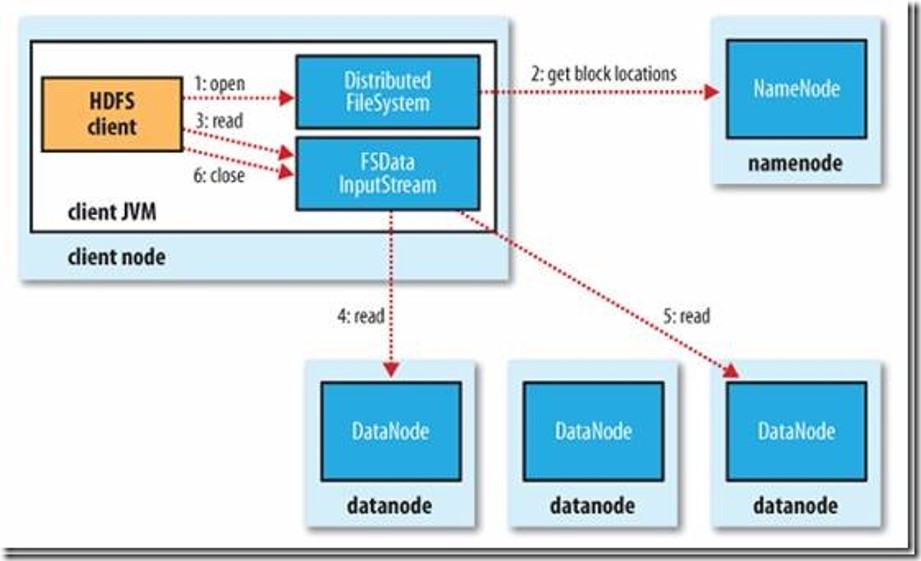
读过程
初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件
FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用stream的read()函数开始读取数据。
DFSInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(client)
当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
失败的数据节点将被记录,以后不再连接。
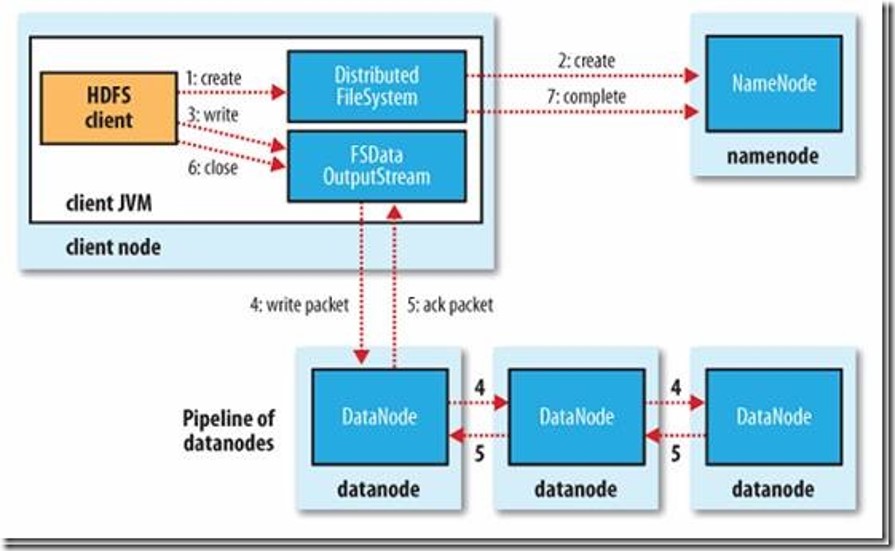
写过程
初始化FileSystem,客户端调用create()来创建文件
FileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
FileSystem返回DFSOutputStream,客户端用于写数据,客户端开始写入数据。
DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
如果数据节点在写入的过程中失败,关闭pipeline,将ack queue中的数据块放入data queue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
HDFS shell
1 | 1,Hadoop fs –fs [local | <file system URI>]:声明hadoop使用的文件系统,如果不声明的话,使用当前配置文件配置的,按如下顺序查找:hadoop jar里的hadoop-default.xml->$HADOOP_CONF_DIR下的hadoop-default.xml->$HADOOP_CONF_DIR下的hadoop-site.xml。使用local代表将本地文件系统作为hadoop的DFS。如果传递uri做参数,那么就是特定的文件系统作为DFS。 |
今天最好的表现,是明天最低的要求。