介绍
数据库其实就是一个普通的计算机系统,为我们提供某种服务。
我们对数据库功能的抽闲可以将数据库功能抽象成三个部分
- 用户API
- 关系代数和事物引擎
- K-V存储
关系型数据库底层也是K-V模型的,但是他为我们提供了更高层的服务,这些服务牺牲了运算速度实现了原子性,一致性,隔离性。
但是有些时候我们需要效率,关系型数据库成了系统的瓶颈。我们需要把速度拿回来,所以一些K-V数据库就产生了,其实就是去掉了关系代数和事物引擎将K-V存储和关于K-V的API暴露给了用户,这就是Nosql,Nosql放弃了事物提高了速度。
但是人们发现最简单的K-V存储好像什么事情都干不了,需要我们处理的事情太多了,就产生了newSql,为我们处理了关系代数模型和事物引擎的一部分功能。
Key-Value存储
本质就是映射,按照key找value。
映射的关键特性 扩展
- 是否支持范围查找
- 是否能够处理更新
- 读写性能指标
- 是否面向磁盘结构
- 并行指标
- 内存占用
- Etc…
常见的数据结构
- 排序数组
- 排序链表
- 跳表
- B tree
- LSM tree
- HashMap
- Fractal Tree
- Red-Black-tree
- COLA
- Etc…
关系代数
primary key:id user_id name
按照key找value, Primary Key:id 按照id查找其他数据。
但是如果按照user_id查看记录,则需要遍历所有记录。效率为O(n)
二级索引
二级索引就是同样也是个K-V映射表 key为user_id,value为主键id。
如果二级索引为Hash结构,效率就下降为0(1),如果是二分查找 Tree,效率为O(logN)
这样查询 先按user_id查找到id,在通过id查找到数据。
如果按照多条件查询 where user_id = 1 and name = ‘tom’
如果按照刚才的索引查找,但是如果user_id为1的记录有一万条,我们就需要遍历一万条记录。
组合索引
扩展阅读
扩展阅读
使用 user_id和name作为key,主键id作为value。
事物简介
事物的核心是锁和并发
- 优势:方便理解
- 劣势:性能较低
事物其实就是帮助程序员人脑来理解程序到底是怎么运转的。人脑永远是串行的。把一个逻辑整理成第一步,第二步,第三步…
但是这要的程序只能在单机单线程中执行。
而现实生活中很多事情都是有先后的,例如我们从bob账户中取钱,我们查询账户余额为100,但我们真的去做减的时候,bob账户中的钱已经被别人取走了。
人脑不能很好的理解并发的概念,所以就设计了一种模式,就是事物,让我们方便理解并发,但是降低了性能。
容易理解的模型性能都不好,性能好的模型都不容易理解 – 这就是生活。
事物单元
其实数据库的DDL操作都可以拆分成两个操作,insert 是先查询再插入,update 先查询再更新, delete 先查询再删除,只有select是一个查询操作。
每次查询的时候都把数据锁上,锁的概念:在线程上面维持一个对这个访问的独占权,其他线程不能再访问它了。
事物所覆盖的所有数据都会被这个线程独占。
但是如果都用这么重量级的锁,那性能就太低了,所以事物为我们提供了四种隔离界别
- 未提交读
- 提交读
- 可重复读
- 序列化
这些也是单独的事物单元
- 商品要建立一个基于GMT_Modified的索引
- 从数据库中读取一行记录
- 向数据库中写入一行记录,同事更新这行记录的所有索引
- 删除整张表
- Etc…
一组事物单元,是顺序执行的,第一个事物单元结束后,第二个事物单元才开始执行。
如果两个事物单元没有任何关系的话,A事物操作bob账户,B事物操作tom账户,两个事物是可以并行的。
如果两个事物共享同一份数据,事物没有办法并行。
事物产生原因
事物单元之间的Happen-before关系(数据的四种冲突)
- 读写
- 写度
- 读读
- 写写
问题
- 如何能以最快的速度完成
- 又能保证上面四种操作的逻辑顺序
mvcc Multi-Version Concurrency Control 多版本并发控制
SQL引擎
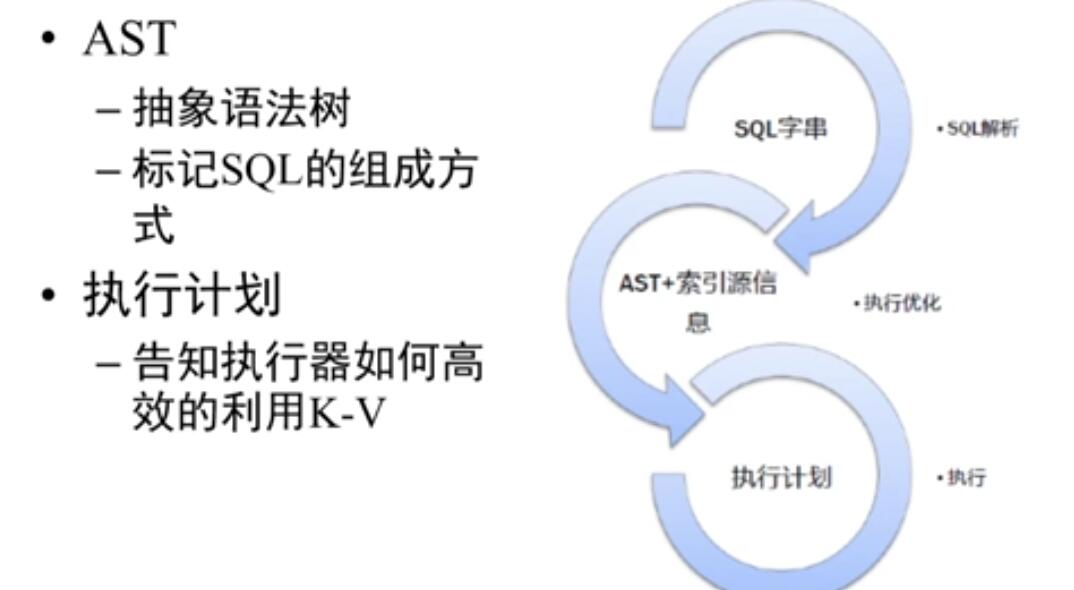
现在主流的数据库都在使用CBO(基于成本的优化)进行系统的操作。
分布式存储
多级K-V存储
关键特性
- 可运维
- 高性能
- 可以比较容易的扩容
- 核心数据结构还是hash和树,部分case针对多机做了一点优化。
代表性组件
- mongoDB -> mongos服务器
- Hbase -> region server + client jar包
- DRDS(TDDL) -> tddl规则引擎组件
分布式结构可以理解成map套map的过程,先查询数据在哪个单机,再做单机查询。
路由
规则引擎:有状态的数据应该按照什么规则进行写入和读取
例如:对pk % 3 —> DB0,DB1,DB2
本质来说还是个查找的过程
- hash
- O(1)效率
- 不支持范围查询(按时间这样的查询条件就比较困难)
- 不需要频繁调整数据分布
- Tree
- 主要是 B Tree
- O(logN)效率
- 支持范围查询
- 需要频繁分裂和合并
- Hash
- Id%n
- 最普通的hash
- 如果id%3 -> id%4 总共会走80%的数据发生移动,最好的情况是倍分id%3 -> id%6,这时候会有50%的数据发生移动
- 数据移动本身就是个要了亲命的事
- hash
- 一致性hash 只要解决数据的扩容和缩容的问题
- 虚拟节点
- 解决热点问题,只需要调整对应关系疾苦
- 解决n->n+1问题,规则可以规定只移动需要移动的数据
- 方案相对复杂
- 一般推荐使用简单方案开始,使用n->2n方案扩容
- 只有需要的情况下,在考虑平滑的扩展到虚拟节点方案。
- B-Tree
- Hbase使用的切分方法
- 支持范围查询
- 对于发部分场景来说,引导列都是pk.userid一类的单值查询,用树相对复杂。
- 需要频繁的进行切分和合并操作 –region server的恶梦
- 固定节点情况下,跨度相对较大,查询效率可能会进一步降低
- Hbase使用的切分方法
一致性
寻求一种能够保证,在给定多台计算机,并且他们相互之间由网络相互连通,中间的数据没有拜占庭将军问题(数据不会被伪造)的前提下(P Partition tolerance 分区容忍性)能够做到一下两种特性的方法:
- 数据的每次成功写入,数据不会丢失,并且按照写入的顺序排列 (C Consistency 一致性)
- 给定安全级别,保证服务的可用性,并尽可能减少机器的消耗(A Availability 可用性)
- 数据的可用性
- 服务的可用性 (响应时间,例如500ms)
无主机方案
- Dynamo/cassandra/Paxos:gossip ,W+R>N (W>N-R) N(node) w(write) r(read)
- 所有节点可写,不存在单点故障
- 读数据的最新版本,需要将所有节点的数据都读出来合并一次
有主机方案(Raft)
主从配置
- Mysql MongoDB Oracle+fibreChannel
- 只有一个节点可写,切换时存在短暂leader election过程,会出现短暂不可写。
- 数据一致性比较好控制,读最新数据只需要读主机就可以,一致性读性能较好。
实际系统需要考虑的问题
- 有些机器负担写任务,因此读压力可能不均衡,因此必须有权重设置。
- 单个节点挂掉的时候,TCP超时会导致业务APP的线程花费更多的时间来处理单个请求,这样会降低APP的处理能力,导致雪崩。
- 因为突发情况,导致数据库请求书增加,数据库相应变慢,导致雪崩。
数据库实践

单机优化原则
- 二分查找效率>全表遍历
- 选择合适的索引
- 内存读写>SSD读写>磁盘读写
- 将物理读(磁盘读)换成逻辑读(内存读)
- 减少锁冲突
- 尽可能通过业务设计,将更新变成插入,来减少加锁去锁的操作
- 减少临时表使用
- 减少多维度排序
分布式系统优化原则
- 减少跨机网络交互
- 尽可能带sharding key
- 分页优化(google一下)
- 减少数据读写热点
- 切分颗粒度尽可能细(用户颗粒度好于省份)
- 减少锁开销
- 尽可能规避分布式事物
总结
- 尽一切可能利用单机资源
- 单机事物
- 单机join
- 好的存储模型
- 尽可能走内存
- 尽可能将以此要查询到的数据物理的放在一起
- 通过合理的数据冗余,减少走网络的次数
- 合理并行提升响应时间
- 读取数据瓶颈,可以通过加slave节点解决
- 写入瓶颈,用规则sharding和扩容来解决
警惕 InnoDB 和 MyISAM 创建 Hash 索引陷阱
今天最好的表现,是明天最低的要求。